NV-EMBED: IMPROVED TECHNIQUES FOR TRAINING LLMS AS GENERALIST EMBEDDING MODELS
论文链接:https://arxiv.org/pdf/2405.17428
代码链接:https://huggingface.co/nvidia/NV-Embed-v2
摘要
基于大语言模型 (LLM) 的嵌入模型在通用文本嵌入任务(包括基于密集向量的检索)中的表现开始超越基于 BERT 或 T5 的嵌入模型。本文介绍了 NV-Embed 模型,引入了新的架构设计、训练流程和精选数据集,显著提升了 LLM 作为通用嵌入模型的性能,同时保持了其简单性和可复现性。在模型架构方面,我们提出了一个潜在注意力层来获取池化嵌入,与均值池化或使用 LLM 中的最后一个 token 嵌入相比,该层能够持续提升检索和下游任务的准确率。为了增强表示学习,我们在对比训练期间移除了 LLM 的因果注意力 MASK。在训练算法方面,我们引入了一种两阶段对比指令微调方法。该方法首先在检索数据集上应用带有指令的对比训练,利用批量负样本和精选的难样本负样本。在阶段 2,它将各种非检索任务融入指令微调中,不仅提升了非检索任务的准确率,也提升了检索性能。对于训练数据,我们利用难样本挖掘、合成数据生成和现有的公开数据集来提升嵌入模型的性能。通过结合这些技术,我们的 NV-Embed-v1 和 NV-Embed-v2 模型在海量文本嵌入基准 (MTEB)(分别截至 2024 年 5 月 24 日和 2024 年 8 月 30 日)的 56 个嵌入任务中取得了第一名,证明了所提出方法的持续有效性。此外,它在 AIR 基准的长文档部分获得了最高分,在问答部分获得了第二高的分,该基准涵盖了 MTEB 之外的一系列领域外的信息检索主题。我们进一步分析了通用嵌入模型的模型压缩技术。我们将该模型开源于:https://huggingface.co/nvidia/NV-Embed-v2。
1.介绍
文本的嵌入或密集向量表示对其语义信息进行编码,可用于许多下游应用,包括检索、重排序、分类、聚类和语义文本相似性任务。基于嵌入的检索器也是检索增强生成 (RAG) 的关键组件,它允许 LLM 访问最新的外部或专有知识,而无需修改模型参数。
多年来,基于双向语言模型构建的嵌入模型一直占据主导地位,但 Neelakantan et al. (2022) 的研究却是一个显著的例外。Wang et al. (2023b) 的最新研究表明,仅使用解码器的 LLM 在检索和通用嵌入任务中的表现可以超越前沿双向嵌入模型。
在本文中,我们引入了 NV-Embed,这是一种通用的嵌入模型,能够显著提升仅使用解码器的 LLM 在嵌入和检索任务中的性能。具体而言,我们做出了以下贡献:
- 在模型架构方面,我们提出了一种新的潜在注意力层,用于获取一系列 token 的池化嵌入。与双向嵌入模型中流行的平均池化以及仅解码器 LLM 中的最后一个 token 嵌入相比,我们提出的池化技术能够持续提升检索和其他下游任务的准确率。为了进一步增强表示学习,我们在 LLM 的对比训练中移除了因果注意力 MASK,从而带来了显著的提升。与相关工作相比,我们的设计更简单,但更有效,因为相关工作需要额外的训练阶段,并包含 mask token 预测或混合训练目标。
- 对于模型训练,我们引入了一种两阶段对比指令微调方法,从预训练的 Mistral-7B 开始。在第一阶段,我们利用批量负样本和精选的难负样本,在检索数据集上进行对比训练。在第二阶段,我们将精心挑选的非检索数据集融入到第一阶段的训练数据中。由于批量负样本在某些情况下会对非检索任务产生误导,我们在第二阶段禁用了批量负样本训练。这种设计不仅提高了分类、聚类和语义文本相似性任务的准确率,而且也意外地提升了检索性能。需要注意的是,我们的模型并未根据现有的嵌入模型进行微调。
- 训练数据是取得最佳成果的关键因素之一。我们提供了详细的训练数据集管理方案,包括数据集特定信息、用于增强对比训练的基于正样本的难负样本挖掘技术、合成数据生成以及基于样例的多类别标注。这使得社区能够轻松复现甚至超越我们的模型,最终推动嵌入模型的发展。
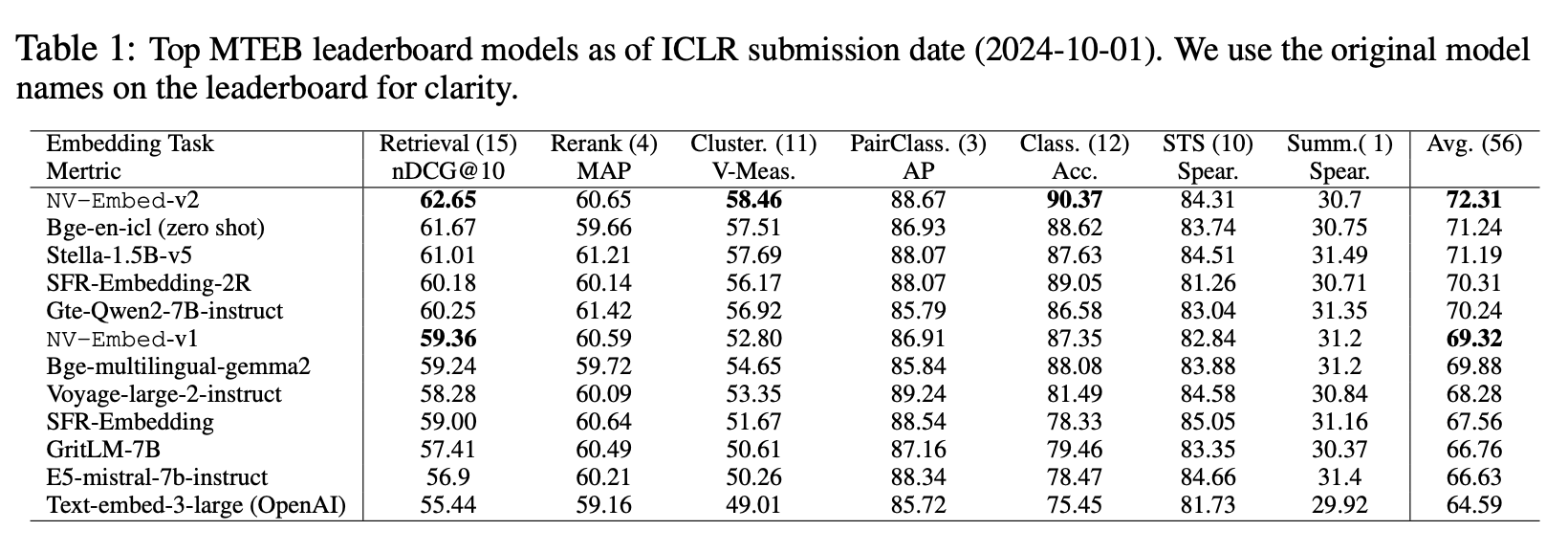
- 我们的 NV-Embed-v1 模型在海量文本嵌入基准 (MTEB) 的 56 个嵌入任务中斩获冠军。通过优化训练数据,NV-Embed-v2 模型创下了 72.31 分的新高,并在竞争激烈的 MTEB 排行榜上重夺冠军宝座(截至 2024 年 8 月 30 日),进一步证明了我们方法的持续有效性。值得一提的是,我们的模型还在 MTEB 基准测试中的 15 个检索任务(通常称为 BEIR)、11 个聚类任务和 12 个分类任务中取得了最高分。详见表 1。此外,在 AIR-Benchmark 的长文档部分,该模型获得了最高分,问答部分获得了第二名。AIR-Benchmark 涵盖了 MTEB 之外的一系列信息检索领域之外的主题。
- 我们研究了基于 LLM 的嵌入模型的模型压缩技术,包括剪枝、量化和知识蒸馏。通过与直接在 Llama3.2-3B、Qwen2.5-3B 和 Minitron-4B 上构建的较小嵌入模型进行比较,证明了我们的模型压缩方法实现了卓越的准确率和量化稳健性。
我们将论文的其余部分组织如下。在§2中,我们讨论了相关工作。在§3中,我们介绍了架构和训练方法。在§4中,我们提供了训练数据管理的详细方法。在§5中,我们展示了实验结果,并在§6中总结了本文。由于篇幅限制,模型压缩技术和结果在§A中展示。AIR-bench 的结果在§B中展示。
2.相关工作
2.1 BIDIRECTIONAL EMBEDDING MODELS
基于 BERT 或 T5 的嵌入模型长期以来一直是通用嵌入任务的主流方法。早期的例子包括 SentenceBERT 和 SimCSE,它们在自然语言推理 (NLI) 数据集上对 BERT 进行微调。通常,这些嵌入模型首先使用预训练的 BERT 或 T5 编码器进行初始化。然后,它们使用精选的无监督或弱监督文本对进行对比学习进行进一步预训练。最后,使用包括 MS MARCO 在内的各种监督数据对嵌入模型进行微调,以用于检索和其他下游任务。需要注意的是,所有最先进的嵌入模型都是以这种监督方式训练的。此类别中一些最新的前沿模型包括 mxbai-embed-large-v1(MTEB:64.68)、UAE-Large-V1(MTEB:64.64)和 voyage-large-2-instruct(MTEB:68.28)。
2.2 DECODER-ONLY LLM-BASED EMBEDDING MODELS
多年来,人们一直认为使用纯解码器的 LLM 在通用嵌入任务上的表现不如双向模型,因为:i)单向注意力限制了表示学习能力,ii)LLM 的规模导致嵌入维度非常高,这可能会受到维度灾难的影响。
Neelakantan et al. (2022) 的早期工作使用预训练的、纯解码器的 GPT-3 模型初始化嵌入模型,并持续进行对比训练。最后一层的隐藏状态(对应于序列末尾的特殊 token )被用作输入序列的嵌入。其最新的后续模型 text-embedding-3-large 的 MTEB 得分为 64.59。最近,E5-Mistral(MTEB:66.63)在 Mistral 7B 上应用了带有任务特定指令的对比学习。通过利用专有 GPT-4 模型中的大量合成数据,它开始在综合嵌入基准测试中超越最先进的双向模型。LLM2Vec(MTEB 得分:65.01)尝试仅使用公开数据从 LLM 构建嵌入模型,但其性能仍然不如 E5-Mistral。
鉴于 E5-Mistral 的成功,SFR-Embedding-Mistral(MTEB:67.56)和 SFR-Embedding-2R(MTEB:70.31)在非检索和检索数据集的混合上进一步微调了该模型,以提高这两项任务的准确性,这与我们的 NV-Embed 密切相关。然而,它们存在以下关键区别:1) NV-Embed 是在 Mistral 7B LLM 上直接使用公开数据从头开始训练的,不依赖于其他嵌入模型或专有合成数据。因此,我们引入了一种新的架构,该架构消除了不必要的因果注意力 MASK,并通过潜在注意力层进一步改进了序列池化机制。2) SFR-Embedding-Mistral 使用任务同质批处理,即构建仅由来自单个任务的样本组成的 batch。相比之下,我们的 NV-Embed 使用由来自所有任务的样本组成的混合批次,以避免潜在的“锯齿形”梯度更新,与 SFR-Embedding-Mistral 相比,这在完整 MTEB 和检索任务上都创下了新高。
在过去的一年里,MTEB 已成为所有 AI 类别中竞争最激烈的排行榜之一,参赛者之间的竞争也显著加剧。许多近期表现优异的模型(例如 stella-1.5B-v5、gte-Qwen2-7B-instruct、bge-multilingual-gemma2、voyage-large-2-instruct 和 text-embed-3-large)尚未披露复现所需的关键技术细节,尤其是所使用的训练数据组合。在近期披露的成果中,GritLM(MTEB:65.66)将文本嵌入和生成统一到一个 LLM 模型中。此外,bge-en-icl(MTEB:71.24)通过在查询端引入少样本示例来增强查询嵌入,并利用文本嵌入任务中的上下文学习 (ICL) 功能。这种方法在训练过程中为查询提供与任务相关的示例,从而增加了开销。为了保持零样本评估准确率,训练过程中会同时包含零样本和少样本。本文重点比较了 bge-en-icl 模型的零样本评估准确率,以确保评估阶段的公平比较。
另一个研究领域侧重于改进数据管理流程,以提高微调检索嵌入模型的准确性。Gecko(MTEB:66.31)尝试通过生成合成配对数据,从纯解码器的 LLM 中提取出更小的双向嵌入模型。它通过为每个查询检索一组候选段落,并使用 LLM 重新标记正样本和难负样本段落,从而提升数据质量。Linq-embed-mistral 利用 LLM 生成、过滤和挖掘负样本,从而优化数据。同时,NV-Retriever 引入了一种正样本感知的难负样本挖掘技术,该技术考虑正样本相关性得分,以更有效地消除假负样本。在本研究中,我们应用这种正样本感知的难负样本技术来管理样本并增强对比训练。
3.METHODS
在本节中,我们描述了我们的架构设计和两阶段指令微调方法。
3.1 BIDIRECTIONAL ATTENTION
在纯解码器的LLM中,因果注意力 MASK 被引入用于下一个 token 预测任务。原则上,解码器模块中的因果MASK允许解码器在自回归文本生成过程中仅关注先前的位置,从而防止信息泄露。然而,我们观察到单向注意力限制了模型的表征能力,GPT模型在自然语言理解基准测试中的表现不如类似规模的BERT或T5模型就证明了这一点。最近,LLM2Vec引入了额外的训练阶段,并利用专门设计的MASK token预测来预热双向注意力。GRIT采用了双向表征学习和因果生成训练的混合目标。相比之下,我们在对比学习中简单地移除了仅纯解码器LLM的因果注意力 MASK,结果显示其效果显著。因此,我们选择了简单的解决方案。
3.2 LATENT ATTENTION LAYER
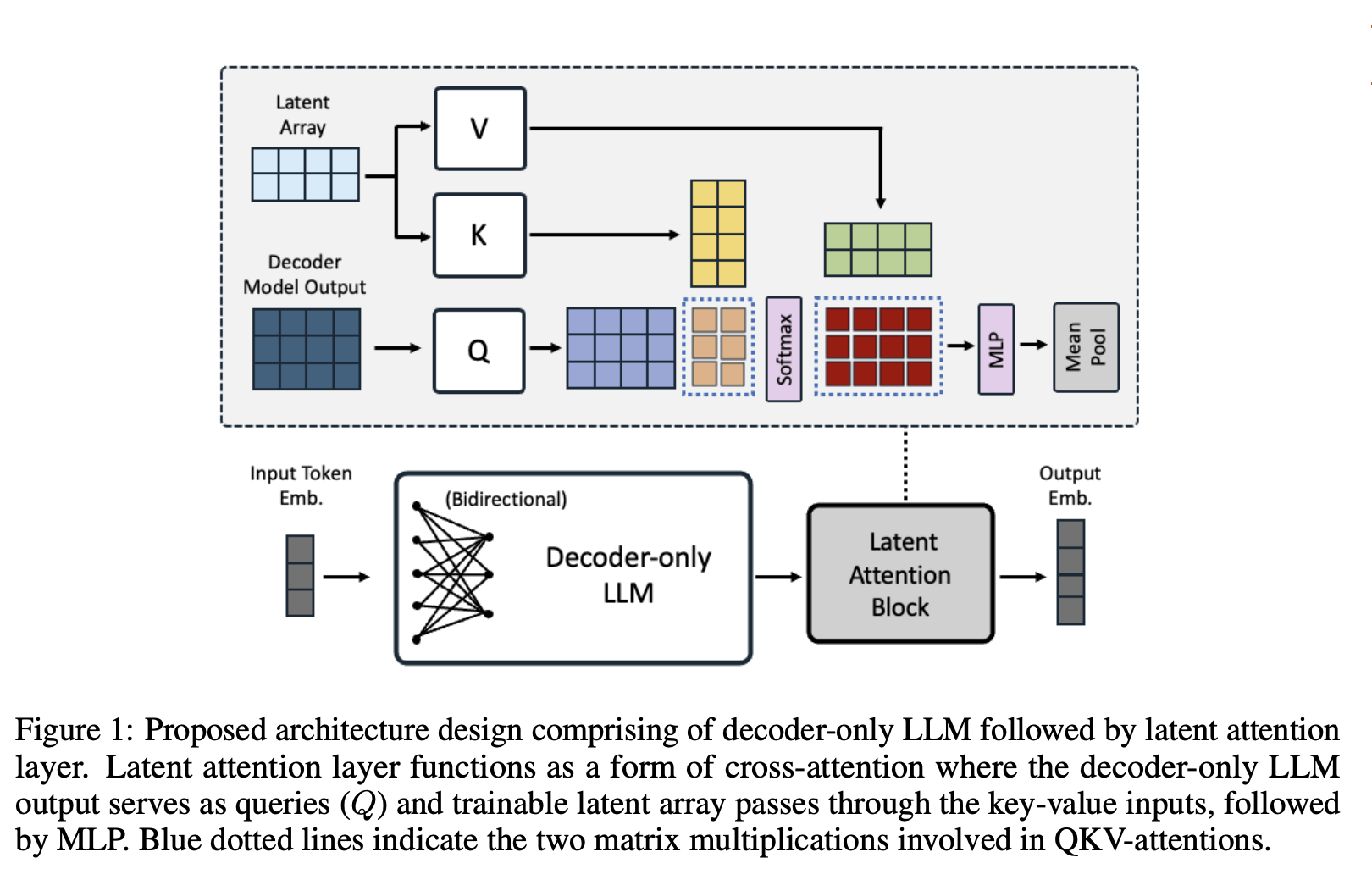
有两种常用的方法可以获取序列 token 的嵌入:i)均值池化;ii)最后一个 token 嵌入。之前的双向嵌入模型通常使用均值池化,而最后一个 token 嵌入在基于解码器的 LLM 嵌入模型中更为流行。然而,这两种方法都存在一定的局限性。均值池化只是取 token 嵌入的平均值,可能会稀释关键短语中的重要信息;而最后一个 token 嵌入可能会受到近邻偏差的影响,严重依赖于最后一个 token 的输出嵌入。
在本研究中,我们受 Jaegle et al. (2021) 的启发,提出了一个潜在注意力层,旨在为通用嵌入任务实现更具表现力的序列池化。具体来说,我们将解码器的最后一层表示为查询 ,其中 是序列长度, 是隐藏维度。它们与潜在数组 一起进行注意力计算, 是一个可训练的“字典”,用于获得更好的表示,其中 是字典中潜在元素的数量。该交叉注意力的输出为 ,
随后是一个常规的 MLP,它由两个线性变换组成,中间有一个 GELU 激活函数。我们的模型使用潜在注意力层, 为 512,头数为 8,用于多头注意力。最后,我们在 MLP 层之后应用均值池化以获得整个序列的嵌入。参见图 1 的说明。值得一提的是,我们的方法遵循字典学习的精髓来获得更好的表示,这与 Perceiver IO 架构不同。我们将提出的潜在注意力层与正常的自注意力进行比较,并在我们的消融研究中发现了一致的改进。
3.3 TWO-STAGE INSTRUCTION-TUNING
指令微调已广泛应用于训练 LLM 遵循指令并执行检索增强生成。近年来,它也被用于训练检索器和通用嵌入模型,这些模型可以根据不同的指令和任务类型调整其输出嵌入。
为了获得一个能够出色地处理检索和非检索任务(例如分类、聚类)的通用嵌入模型,我们需要考虑不同任务的特点。例如,使用批量负样本已被证明对于训练基于密集嵌入的检索器非常有效,因为它可以重复使用计算,并在每个小批量中仅包含 B 个问题和相应的正样本段落,有效地对 个问题/段落对进行训练。然而,使用批量负样本技巧可能会误导用于分类或聚类任务的嵌入模型,因为小批量中的“段落”可能来自该类别,并且不是负样本。
鉴于这些考虑,我们引入了一种两阶段指令微调方法。首先,我们使用指令在各种检索数据集(详见 4.1 节)上进行对比训练,并利用批量负样本和精选的难负样本。在第二阶段,我们结合检索数据集和非检索数据集(详见 4.2 节)进行对比指令微调,而不使用批量负样本的技巧。值得一提的是,检索任务的难度高于其他任务,因此我们的训练策略最初侧重于对检索模型进行微调。在第二阶段,我们将其余的嵌入任务融入指令微调中。
4.TRAINING DATA
对于训练数据,我们使用公开的检索数据集、非检索数据集以及合成样本,以展示我们模型在嵌入任务中的能力。我们的训练过程融合了检索和非检索任务,包括分类、聚类和语义文本相似度数据集。
给定相关的查询-文档对,查询遵循如下指令模板:
表 12 和表 13 分别提供了训练阶段和评估阶段每个 {task_definition} 的指令模板。需要注意的是,我们在训练和评估阶段都屏蔽了输出嵌入中的指令 token,尽管由于自注意力机制的影响,它们仍然会影响输出。我们没有在文档语料库中添加任何指令前缀。
4.1 PUBLIC RETRIEVAL DATASETS
我们采用的检索数据集如下:MSMARCO、HotpotQA、Natural Question、PAQ、Stack Exchange、Natural Language Inference、SQuAD、ArguAna、BioASQ、FiQA、FEVER、HoVer、SciFact、NFCorpus、MIRACL 和 Mr.TyDi。
值得注意的是,某些数据集(例如 MSMARCO)是 MTEB 基准的训练样本,我们遵循领先的通用嵌入模型所建立的现有实践。表 12 进一步提供了用于训练的样本数量。我们在附录 B 的 AIR-bench 上演示了 NV-Embed 的零样本泛化能力。
4.1.1 HARDNEGATIVE MINING TECHNIQUE
嵌入模型采用对比学习进行训练,旨在提高查询词嵌入与其相关段落(正例)之间的相似度,同时降低与不相关段落(负例)之间的相似度。公共检索数据集通常仅包含正例查询-段落对,而不包含其自身的难负例,因此有必要挖掘此类负例。为了解决这个问题,我们应用了最近提出的正向感知难负例技术,该技术考虑了正例相关性得分,以更好地去除假负例。借鉴 Moreira et al. (2024) 中的消融研究,我们使用 E5-mistral-7b-instruct 作为教师检索模型,以识别与查询相关的最优难负例段落。我们根据正例得分 (TopKPercPos) 的百分比设置负例得分的最大阈值,其阈值为 95%,具体表达式为:。
4.2 PUBLIC NON-RETRIEVAL DATASETS
除了检索数据集外,我们还利用了公开的非检索数据集,这些数据集主要来自 MTEB 基准测试中的三个子任务:分类、聚类和语义相似性 (STS)。我们对这些数据集的格式进行了预处理,使其与用于对比训练的检索数据集兼容:查询 、正文档 和难负文档 。
对于分类,我们利用 MTEB Huggingface 数据集中各种数据集的英语训练数据。我们使用的分类数据集如下:AmazonReviews、AmazonCounterfactual、Banking77、Emotion、IMDB、MTOPDomain/MTOPIntent、ToxicConversations、TweetSentimentExtraction、AmazonPolarity、MassiveScenario/MassiveIntent。对于 Emotion 和 AmazonCounterfactual 分类数据集,我们使用 BM25 相似度阈值来过滤与 MTEB 评估集相似的训练数据。
对于聚类数据集,我们利用来自 MTEB Huggingface 数据集、TwentyNewsgroups、Reddit、StackExchange、RedditP2P 和 StackExchangeP2P 的 raw_arxiv、raw_biorxiv 和 raw_medrxiv 数据集,我们过滤掉与 MTEB 评估集匹配的任何训练数据。
分类和聚类数据集提供样例和相应的类/簇标签。从相应的 text/title/abstract 字段中提取的示例文本用于查询 。对于二分类任务,标注文本用作文档 和 。对于多类分类和聚类任务,从当前类/簇中随机抽取的示例用于正类文档 ,从其他类/簇中随机抽取的示例用于负类文档 。我们将在 5.2.4 节中介绍支持此方法的消融实验。
对于语义文本相似性数据集,我们使用来自 MTEB Huggingface 数据集的三个语义相似性数据集 STS12、STS22 和 STS-Benchmark 的训练样本。对于任何具有相关相关性得分 的文本对,如果 score ≥ 4,我们创建两个样本 和 。我们使用与 4.1.1 节相同的技术,从其他文本池中挖掘难样本 。由于 和 与查询对称,因此任务指令被附加到它们之后。
4.3 SYNTHETIC TASKS DATASET
由于公共训练数据集中主题和任务的多样性有限,可用的训练指令模板也受到限制。为了增强任务级泛化能力,我们采用 Mixtral-8x22B-Instruct-v0.1 模型 (MistralAI) 创建了一个包含 60,000 个合成任务的 120,000 个合成示例的数据集。遵循 E5-mistral-7b-instruct 提出的两步提示方法,我们针对 Mixtral-8x22B-Instruct-v0.1 和英文文本调整了提示。由于我们使用公共 STS 数据集且不评估双语文本检索任务,因此我们仅生成短-长、长-短和短-短三种类型的示例(每种类型各 40,000 个)。合成数据生成的示例提示可在附录 15 和 16 中找到。